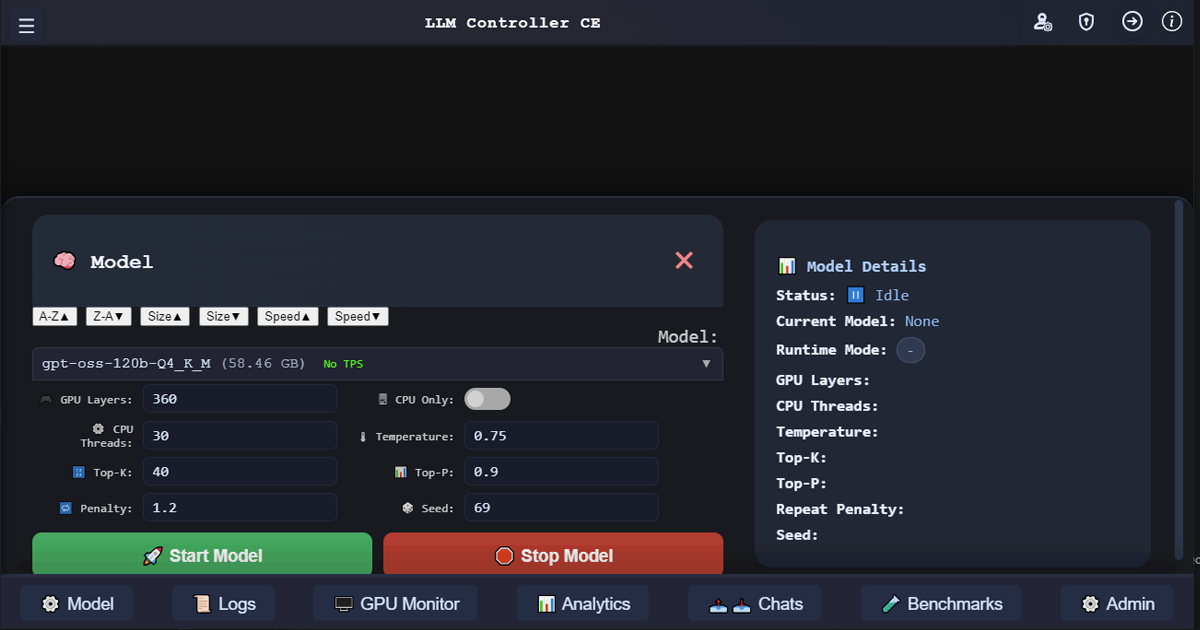
Admins scan GGUF folders, govern the registry, load and stop local GGUF models, and save llama-server runtime defaults.
💬 Chat-First Workflows
Signed-in users chat with the loaded main model, stream responses, stop generation, regenerate replies, edit prompts, and manage saved chats.
📎 File-Aware Conversations
Attach supported text and code files directly to prompts, with server-side limits, chunking, context budgeting, and persistence in saved conversation turns.
🖥️ Runtime Visibility
Watch live llama-server Logs, runtime status, active process visibility, and GPU Monitor data from local NVIDIA or AMD tools where available.
📊 Analytics & Benchmarks
Review runtime Analytics and run admin-managed Benchmarks with editable prompts, live progress, best-run tracking, and result drill-downs.
⚙️ Installation & Settings
Bootstrap the Community Edition with first-run installation, runtime path settings, user administration, and local configuration.
What LLM Controller CE Includes
Self-hosted, local-first browser app for operating local GGUF models through a configured llama-server executable.
Admin-controlled GGUF discovery, registry state, llama-server loading/stopping, runtime settings, and readiness-aware model status.
Normal signed-in users chat with the currently loaded main model and manage their own chat history.
Streaming chat with Markdown, code blocks, math rendering, reasoning panels, attachments, regenerate, and prompt edit workflows.
Runtime Visibility with live llama-server Logs, GPU Monitor data where local tools are available, active process visibility, Analytics, and Benchmarks.
Installation & Settings for first-run bootstrap, Windows launcher support, configurable Linux paths, users, and administration.
No cloud service required.
Get Release Updates
No spam. Just release notes, wiki updates, and important project news.
LLM Controller
LLM Controller CE
About LLM Controller
LLM Controller CE is a local-first dashboard for running and managing Large Language Models on your own hardware.
It lets you launch, switch, and monitor models like Llama and DeepSeek with zero cloud dependencies, full privacy, and real-time insight into performance and GPU usage.
Built on llama-server, it automatically detects supported GPU runtimes and supports advanced multi-GPU and dual-model setups without manual configuration.
Key Features
Model Management: Scan, launch, stop, and switch models instantly.
Live Analytics: Logs, GPU telemetry, token throughput, and latency metrics.
Modern Chat UI: Streaming output, Markdown, code, math, and titles.
Local & Private: 100% self-hosted. No cloud, no data sharing.
Actively Developed: Built to evolve with new models and features.